Background
Korea has experienced dramatic changes in population aging, along with rapid socioeconomic development. Declining fertility and increased life expectancy have had a major impact on population aging. In 2020, the proportion of the population aged 65 and over has reached 15.7% (Statistics Korea, n.d.), increasing each year at a rapid rate. With the aging of Korean baby boomers, born 1955-1963, population aging is gaining even more speed and the over-65 population is projected to reach 20% by 2025, according to Statistics Korea.
The issue of rapid population aging was raised only after the millennium, when the government became alarmed about its speed. The seriousness of the phenomenon accelerated the implementation of three five-year basic plans; nonetheless there was a lack of social consensus about how to address this issue. Looking at the precedents of developed countries that experienced population aging earlier, how the public recognizes aging could be extremely important in that not only could it lead to indifferent and unfavorable opinion towards policies but also could lead to serious social discordance such as intergenerational conflict and gerontophobia. Thus, this study aims to analyze how Korean society recognizes aging and how social discourse on aging has changed periodically with the purpose of suggesting priority issues and policy focus that could contribute to building a cooperative and inclusive super-aging society.
However, it is not an easy task to recognize public opinion and social discourse on aging because aging covers vast range of issues and perspectives.
One significant method to track public opinion is to analyze the media. In modern society, media plays a critical role in forming public perceptions of reality. In particular, newspaper articles are expected to maintain objectivity and as such, are often accepted as reality itself; public opinion may be affected and formed by discourses produced by newspapers (Jang, 2013). Thus, by analyzing the discourse on aging produced by the media, it is possible to uncover public opinion and the main elements of discourse on aging. Owing to technological development in an era of Industry 4.0, vast amounts of media texts have been digitized; the methodology by which fundamental insights and solutions may be drawn from such materials have been elaborated. This study aims to take advantage of such technological benefits and explore the structure of social discourse on aging by analyzing newspaper articles on aging, with the ultimate purpose of providing future policy implications.
Theoretical Background
Social Discourse and Media
Studies on discourse typically regard discourse as a social practice of participants communicating through linguistic and semiotic resources under certain contexts. Discourses are composed of vocabularies and rhetorical techniques as well as modes of thinking, grammars, rationalities, and even specific material practices that represent, interpret, and create new reality. Thus, discourses are seen as frameworks for understanding and directing different domains of social action.
Although various strands could be found within theories on discourse,[1] they generally articulate three problems: power, knowledge and subjectivity. Not only is discourse shaped by power structures, but it also contributes to objectifying and constituting power structures by representing them. As a socially-situated activity of producing meaning, discourse produces and legitimizes knowledge within society. Furthermore, discourse plays a crucial role in constructing subjectivity as it defines, identifies, and creates actorhood by attributing places and positions to those who enter discourse (Angermuller, 2015). Such a viewpoint follows the works of Foucault, who refers to “discourse” as ways of constituting knowledge, together with social practices, forms of subjectivity and power relations which inhere in such knowledges and relations between them (Diamond & Quinby, 1988). Foucault focuses on questions of how some discourses have created meaning systems that dominate the way we define and organize ourselves and our social world while other discourses have been marginalized and subjugated.
Thus, discourse is ideological, reflecting inequal power relations within society, and the main objective of analyzing discourse lies in disclosing the ideological structure that lies beneath discourse, mostly presented in the form of text.
A majority of the research on discourse focuses on the significance of media text. Media in modern society not only provides knowledge and information but also forms individual’s perception and practice within society. Media selects or excludes, as well as emphasizes or conceals information following certain ideological criteria. In this sense media is the site where competing discourses on important social agenda collide, gain dominance, and are dispersed and consumed. Therefore, considering the significant role media is playing in modern society, it is reasonable to take media discourse as a proxy for social discourse and public opinion.
Research Analyzing Media Discourse on Aging in Korea
Among the vast range of previous research on aging, it is disappointing to find very little research analyzing the media discourse of aging in Korea. Han and Yoon (2007) take the initial step in this area. They critically review 1,725 newspaper articles from 3 major newspapers between 1997-2006 containing either “aging” or “elderly” within the text. They found an increase in the articles portraying positive images of aging in Korea by introducing new discourse such as “successful aging,” which emphasizes a productive and active lifestyle for the elderly. On the one hand, they welcome the change in trend brought by successful aging discourse, altering the negative images of elderly as a dependent burden on society. On the other hand, they warn that an overemphasis on successful aging might lead to stereotypes of the elderly and unintentionally marginalize certain groups of people who cannot meet the standards, i.e., disadvantaged elderly or elderly women in low socioeconomic strata.
Kim (2017) starts by questioning how society recognizes the elderly and conducts media discourse analysis on aging. In the era dominated by neo-liberalist ideology, all human existence is driven into infinite competition, forcing people to increase their market value. The research suggests that elderly people are not exceptional in this respect. In order to be a welcoming member of society, the media imposes social discourses on elderly people to be functional as socio-economic agents within society. Independence is a proxy for a wonderful later life, subjective youth as a core value of old age underlies being economically productive throughout one’s lifespan. The study concludes that such media discourse may conceal the societal responsibility of caring for the elderly and marginalizing a majority of older people. Although Kim’s (2017) study was published almost a decade after Han’s (2007) work, both have the same context.
Lee and Kim (2019) conducted analysis online social media posts from 2004 to 2017 related to aging and the elderly, with the purpose of identifying major themes and temporal trends of discourse on the elderly. Prior to analysis, they theoretically identified significant factors affecting the lives of older people and generated four domains, which are economy, health, relationships, and culture. Based on literature review, they constructed a noun dictionary for each domain. Web crawling and social network analysis was implemented. The analysis found that quality of life of older people is placed at the center of the discourse and has a strong association with economic welfare and health status. Poverty, jobs, and dementia appeared as the most salient themes. Furthermore, a sense of alienation and isolation in interpersonal relationships was closely related to mental health and quality of life.
In summary, previous research was fruitful in supporting the idea that the media plays some role in framing the discourse or image of older people. However, analyzing large media texts focusing on the underlying discourse structure on aging is yet an unexplored field.
Method
Data Collection
The data analyzed in this article was collected from the newspaper digital archive, Big KINDS (Korea Integrated Newspaper Database System), provided by the Korea Press Foundation. Big KINDS is a news analysis service that provides metadata information by combining a big data analysis technique and news media. It provides over 6.5 million news contents collected from 54 media of all kinds, such as daily newspapers, financial newspapers, local newspapers, and newscasts dating from 1990. Due to copyright issue, Big KINDS provides metadata files consisting of keywords and feature-extracted words generated by morpheme analysis instead of the original text. The keywords contain all the words and phrases extracted from the original article while most of the stop words[2] are excluded. On the other hand, feature-extracted words are derived by applying the Text Rank algorithm to the keywords generated by morpheme analysis with the purpose of suggesting word groups of higher importance (Park et al., 2017).
Articles were identified with a search algorithm that includes the word “aging” in the title between 2006 and 2019, a time period during which the first, the second, and the third government “Basic Plan on Aging Society and Low Fertility” were put into action. Financial newspapers and local newspapers were excluded under concern of deviation towards either economic or local issues. Collected articles were screened manually to ensure that they fit the inclusion criteria and as a result, a corpus of 1,472 texts was collected. The number of articles varied by year, showing the ebb and flow of media interest in aging issues. As previously mentioned, Big KINDS provides metadata for each article and this study used the keywords of each document for analysis. By so doing, it was possible to avoid the labor of noun extraction and stop word elimination.
Analysis Tools and Techniques
All data handling, screening, preprocessing, and analysis was performed via R version 3.6.2. The main R packages used for analysis were dplyr, ggplot2, KoNLP[3], lda, ldatuning, stringr, tidytext, tm, and topicmodels.
The analysis for this study is composed of three stages: first, tidying the text and preprocessing; second, topic modeling; and third, time-series analysis of changes in topics.
Preprocessing is composed of stripping empty spaces, eliminating numbers, punctuation, special characters, and, last but not least, extracting stop words (Baek, 2019). This study used the tm package and stringr package to accomplish basic text tidying job. While preprocessing is generally acknowledged as the most burdensome yet critical component of successful topic modeling, most of the burden can be avoided by using the preprocessed keywords provided by Big KINDS. However, because the keywords are mainly nouns extracted from the raw material based on morpheme analysis, some words and phrases may lose their original meaning being decomposed into morphemes. This study combined important word chunks and phrases such as “baby+boomers,” “salary+peak,” “national+pension,” “social+insurance,” “elder+abuse,” etc.,[4] detected by running frequency to avoid losing meaning.
Text mining is basically a method to determine what a document is about by quantifying the words that make up a document. A simple way to decide how important a certain word is to the document is to look at its frequency. However, the texts at hand are from the same theme (generally the study theme) and thus share words in large frequency that could not be regarded as stop words (in the case of this study: aging, elderly, fertility, etc.). When extracting topics from the set of documents (corpus), these words could act as noise, disturbing exact analysis and interpretation in the same way as stop words. Applying the statistic tf-idf is a useful way to solve this problem. Tf-idf[5] is intended to measure how important a word is to a document in a corpus by decreasing the weight for frequently used words while increasing the weight for those less commonly shared within the corpus but having significance within a specific document. The tf-idf score is 0 or near 0 for common words (Silge & Robinson, 2017). This study used the tidytext package to calculate the tf-idf score for each word in the corpus. The calculation showed 30 words with tf-idf value less than 0.01, and all 30 words were removed from the corpus.[6]
The second and focal part of analysis, topic modeling, is a valuable method for identifying the linguistic contexts that surround social institutions or policy domain (DiMaggio et al., 2013). There are several kinds of topic modeling techniques among which Latent Dirichlet Allocation (LDA) is especially popular. The LDA model is a probabilistic model that identifies sets of words, or “bags of words,” that co-occur across documents. LDA is called a “topic model” because the identified sets of words tend to reflect underlying topics that, in combination, characterize every document in a corpus (Blei et al., 2003; Blei & Lafferty, 2006; Liu et al., 2016; McFarland et al., 2013).
One of the main challenges of topic modeling is to identify the number of topics that are latent in the corpus. There have been a number of approaches to validate the number of topics, one of which is to rely on model fitness scores of a given number of topics calculated via the FindTopicNumber() function.[7] As Baek (2019) claims, the FindTopicNumber() function in the ldatuning package is convenient to use not only because it is possible to input plural k (number of topics) simultaneously, but also because it calculates four different model fitness scores at the same time, allowing for a more comprehensive determination of the number of latent topics. The four model fitness scores estimated in the ldatuning package are Griffiths2004, Deveaud2014, CaoJuan2009, and Arun2010. The four of them differ in their details but share the same objective of calculating the number of topics that group words in a most distinctive way.[8]
The final part of this study measures the load of topics for each year (as sums of those word-sets, or number and percent of documents using those words), to plot time-serial changes. To observe such time-series variation of latent topics, this study employed the same analytic model previously implemented by Roh and Yang (2019). Each document (newspaper article) was assigned to a topic based on LDA estimation, specifically the gamma value, which indicates the degree of affiliation of a document to the topics. Each document was assigned to the topic with largest gamma value. Nevertheless, documents with a largest gamma value smaller than average, were omitted from topic assignment.
Results
Topic Extraction and Definition
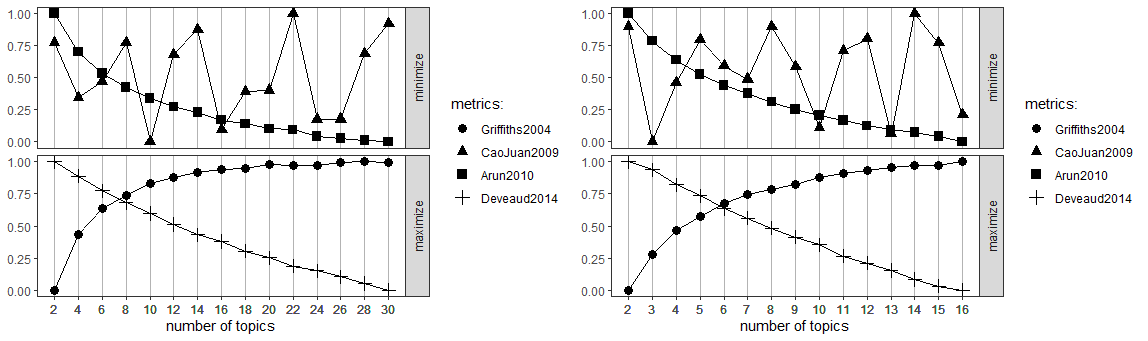
The result of model fitness estimation of the number of topics is shown in Figure 1. For the primary estimation, the number of topics input was 2 to 30 with an interval of 2 (left graph). Because the four scores indicate different directions, deciding on the appropriate number of topics is quite complicated. The CaoJuan2009 score fluctuates whereas Arun2010 decreases with the number of topics. The lowest converging scores of the two is 16. As for the Griffiths2004 and Deveaud2014, they go in totally opposite directions. The two converge somewhere around 7 or 8, but afterwards, the Deveaud2014 becomes too low. Griffiths2004 continually increases but turns quite flat around 16. Put together, the appropriate number of k seems to be between 2 and 16. The second estimation was implemented with a narrower range of topic numbers, starting from 2 to 16 with an interval of 1. The result is the right-hand side graph of Figure 1. CaoJuan2009 and Arun2010 converge at 10 and 13. However, the scores for Deveaud2014 at 10 and 13 are too low (below 0.5). The next lowest converging point of CaoJuan2009 and Arun2010 is 7 and the scores for Griffiths2004 and Deveaud2014 are both reasonably high at k=7. Thus, the number of topics, k, was set as 7.
.png)
The 7 topics extracted via Latent Dirichlet Allocation model are summarized in Table 1. Listed in Table 1 are the 20 keywords of each topic with the highest beta value[9] in the order from most important to least important. Different topics might share the same words since LDA is an admixture model (Sutherland & Kiatkawsin, 2020). In order to clarify the theme of each topic, it is necessary to observe not only the keywords but also the headlines of articles most representative within the topic. Deciding the representativeness of an article within the topic can rely on the Gamma value generated from the LDA model, as is shown in Table 2.
Topic 1 includes core keywords such as elder abuse, elderly living alone, and crime towards the elderly. However, keywords show a large variation by including words such as blood donation, voters, candidates, etc. Such confusion can easily be solved by observing newspaper headlines. By taking the newspaper headlines into account, we can conclude that Topic 1 is closely related to various social issues that can arise in an aging society. Consequently, the theme for Topic 1 was determined to be miscellaneous social issues of an aging society. Topic 2 holds keywords associated with death or illness (death, dementia, pneumonia, cancer, etc.). By synthesizing the extracted keywords and newspaper titles belonging to Topic 2 we can note that Topic 2 is about death related issues or causes of death in an aging society. Some of the keywords seem to be protruding and bizarre (e.g., separate families[10]), but newspaper headlines indicate that these words are also related to death. Thus, the second topic could be labeled as issues relating to death of aging. The main keywords for Topic 3 are drivers, service, insurance fee, etc. Articles belonging to Topic 3 are mostly related to private insurance market issues as shown in Table 2. Therefore, private insurance market could be an appropriate naming for Topic 3. The underlying theme for Topic 4 is rather obvious since many keywords point to the economic side of an aging society. The newspaper headlines also confirm that Topic 4 is related to economic growth in an aging society. Healthcare costs, welfare expenditure, GDP, etc. are keywords allocated to Topic 5; thus, Topic 5 can be labeled as national debt or burdens of an aging society. Topic 6 contains words related to labor market issues. Labor market innovation has been regarded as one of the key elements in tackling an aging society, as is shown by the newspaper headlines for Topic 6. Last, many keywords in Topic 7 are specifically about the national pension scheme. However, a wider range of words could be found, such as private pension, retirement pension, and retirement age extension, indicating that Topic 7 could be labeled income security in an aging society, a broader term than national pension.
In the next section, the result of a time-series analysis of how these topics change by year will be explained, with the purpose of suggesting policy implications.
Topic Dynamics over Time
Table 3 shows how the topics and percentage of documents referencing these array of topics changes over time. Notably, most topic loadings increase over time. These changes could be interpreted differently based on different perspectives. First, because the digital corpus has become larger over time as more and more documents get digitized, indicating that quantity is not a suitable means for illustrating change. From a different perspective, increase in the quantity might reflect increased media interest about aging. In any case, we should take caution in imposing too much meaning on quantity. However, Table 3 shows that, although topic loadings generally increase with time, they fluctuate from time to time. It is noticeable that topic loadings increase during the last year of a government basic plan implementation cycle, the years 2010 and 2015, probably because it is also a period of introducing and publicizing the new five-year basic plan.
Focusing on each topic, the result shows social issues, death, and private insurance topics received relatively minor attention from the media compared to other issues. The social issues topic was a major issue covered by the media during the first basic plan era and mainly received public attention during the first and last year of basic plan implementation. The private insurance topic shows the tendency to increase recently, during the third basic plan era. The economic growth topic seems to be gaining more attention recently, but if we compare the relative portion of economic growth to all the topics, it is noticeable that the loading is quite stable over time. Topic loading for national debt and labor market innovation are the most prominent topics; not only have they increased over time, but they have been the most frequently discussed topics during the third basic plan era. It is surprising to note that the topic income security has not been of much interest, relatively speaking, in the media considering the high poverty rate of older people in Korea, suggesting a momentary media interest in the income security issue.
Discussion
This study focused on the use of probabilistic topic models of newspaper articles to find the public discourse structure on aging, how it has changed over time, and what implications it has for the future of the super-aging Korean society. The findings can be summarized as follows:
First, compared to 2006, the quantity of media discourse on aging has increased sharply within recent years, showing an increased public interest on aging. Even though Korean society became more aware of population aging shortly after the year 2000 the statistics show that public interest was only minor or superficial before 2010. After transient interest in 2006 when the first five-year national plan on aging was announced and implemented, media discourse on aging decreases noticeably. The year 2010 records a turning point, as the quantity of newspaper articles on aging increases consistently afterwards, indicating that aging has become a major public issue in Korea. However, within the overall upward trend exists five-year sub-trends. Media discussion on aging tends to increase noticeably during the final year of national basic plan implementation (i.e., 2010 and 2015), a period when the next basic plan is prepared and publicized, implying the government policy impacts media discourse.
Second, seven latent topics were derived from the LDA model, which can be identified as social issues, death, private insurance, economic growth, national debt, labor market innovation, and income security. The topic loadings varied by year but demonstrated a clear increase in public interest on certain topics. Specifically, the topic loadings of the year 2006 show, by and large, a balanced distribution among topics while economic growth gained little interest from the media. However, longitudinal changes in topic loadings show a marked increase in economic growth (5.53 in 2006 to 28.74 in 2019), national debt (18.32 in 2006 to 46.59 in 2019), and labor market innovation (11.89 in 2006 to 46.54 in 2019).
It is possible to infer from such results that the aging discourse shaped by the media has become more inclined to address efficiency and productivity issues. Regarding the fact that Korean society is facing some highly controversial issues, such as high poverty and the suicide rate of older people, productivity-focused discourse on aging might result in negative social effects. As Kim (2017) asserts, productivity focused discourse on aging forces older people to be productive subjects. They are recognized by society as economic participants obliged to fulfill a productive role within society. Such subjectivation connotes a decreased role of the government and society by shifting the responsibility to individuals. In this respect, a lack of material as well as non-material resources that older people in Korea are faced with is the result of maladjustment within the labor market and thus the responsibility of individuals. As media discourse on aging is shaped towards recognizing older people as independent and productive citizens focusing on providing opportunities in the labor market, social issues and problems can be marginalized. In reality, older people who successfully adapt to the changing environment and become independent subjects within the market are only a minority, while the majority of older people are in need of societal care and support. Furthermore, public expectations for independent and productive older people shaped by aging discourse can lead to an aversion towards the majority of people, who fail to satisfy this standard. Gerontophobia isn’t a serious issue in Korea yet but is always possible, considering the highly competitive and harsh social environment younger generations are facing, an environment that disrupts traditional values such as respect for elders.
One final issue to address concerns the methodological limitations of this study. This study focused on using big data analysis, specifically topic modeling via Latent Dirichlet Allocation. Although LDA is a widely used topic modeling technique, it suffers from “order effects,” which occur when the order of data is shuffled, generating different topics. This limitation can be quite controversial since it can cause systematic errors and lead to misleading results such as inaccurate topic description (Agrawal et al., 2018). Experts in computer science and information technology are working to find a method that generates more stable LDA results, but it still needs to be elaborated. Nevertheless, readers must take into account that big text data analysis as a method is only at the beginning stages and more research is necessary to tackle such limitations.
Funding
Funding for this paper was provided by Namseoul University year 2020.
Angermuller (2015) suggests that at least three strands could be distinguished within discourse theory: post-structuralist, normative-deliberative, and critical-realist discourse theories.
Stop words are words without much meaning or information such as prepositions, pronouns, etc. These words are filtered out in processing natural language data in order to save space and time.
The text data for this study is in Korean and thus KoNLP package, a morphological analyzer for Korean text-based research, was used.
The importance of word chunks was decided upon based on theory and policy (Basic Plan on Aging Society and Low Fertility). It is agreed upon that preprocessing and interpreting textual data is a complicated job and in many cases requires a lot of supervised approach to use textual data effectively.
The statistics tf-idf is theoretically based on Zipf’s law, stating that the frequency of a word is inversely proportional to its rank.
The list of 30 words removed are as follows (in increasing order of tf-idf score): aging, Republic of Korea, low fertility, our country, Seoul, Bureau of Statistics, municipal government, spouse, systematic, elementary school, jobs, living costs, OECD (in Korean), OECD (in English), daycare center, persons concerned, report, continually, Gyeonggi province, youths, researcher, developed countries, families, public institutes, age group, point, the Bank of Korea, commission, elderly, fertility rate.
This study chose the ldatuning package for assessing the fit statistics of different levels of topic k. It is necessary to take two steps in order to get the optimal number. First, to input the largest possible number of k with a large interval (i.e., the number of k starting from 1 till 30 at the interval of 5) and depending on the output, to narrow the number of k and the interval until concluding the optimal number.
For Griffiths2004 and Deveaud2014, the number of topics with a larger score has better fitness whereas a smaller score implies a more optimal LDA model (Baek, 2019).
The beta value implies highest relative probability of belonging to the given topic (Sutherland & Kiatkawsin, 2020).
Many readers from outside Korea might be unfamiliar with the phrase separate families. Separate families mean people from North Korea who have been separated from their families and relatives in the course of the Korean War (1950-1953). The South Korean government has been trying to negotiate with the North Korean government to make opportunities for those families to meet. Nonetheless, there are still many people who haven’t had the opportunity, since the event largely depends on both countries’ relationship.